In this tutorial, we will talk about how to make a word cloud picture with your picture and text.


These are wordcloud examples I did in the past projects
First, you need to install python and the required packages. I suggest using pip install for package installations, here are the packages we need to install
pip install wordcloud
pip install matplotlib
pip install scipy
pip install nltk
pip install imageio
You can choose whatever picture you like for the wordcloud, the only requirement is the picture must have a transparent background. Please check out this tutorial on how to make an image background transparent using the free online editor Pixlr. I used Steve Jobs - One of the most innovative people in Tech. Here’s the picture that I use for the wordcloud:

Steve Jobs PNG image. Retrieved from http://pngimg.com/download/33423
After you chose your picture, it’s time for us to choose our speech. I used Steve Jobs’ 2005 Standford Commencement address. Here’s the link for the speech. If we take a look at that speech, we will find that there is a lot of stuff we don’t want to put in the word cloud picture, e.g, numbers, abbreviations, pronouns, conjunctions (“for”, “or”), etc. That’s why we need to use the NLTK in python. Let’s use the first sentence of the speech as an example. We will first convert the sentence to its atomic elements, then remove meaningless words.
1.Converting the sentence to its atomic elements
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'[A-Za-z]+') #Regex with only word characters
string = 'I am honored to be with you today at your commencement from one of the finest universities in the world.'
raw = string.lower()
tokens = tokenizer.tokenize(raw)
print(tokens)
>>['i', 'am', 'honored', 'to', 'be', 'with', 'you', 'today', 'at', 'your', 'commencement', 'from', 'one', 'of', 'the', 'finest', 'universities', 'in', 'the', 'world']
2.Removing meaningless words(stop words). You can find the list of stop words that we are using in this case here
from nltk.corpus import stopwords
stop_words = stopwords.words('english') #English stop words list
stopped_tokens = [word for word in tokens if not word in stop_words] # extract all the non-meaningless words
print(stopped_tokens)
>>['honored', 'today', 'commencement', 'one', 'finest', 'universities', 'world']
Now, we can apply these techniques to our speech. It’s easier to import the speech to python if we save it as a text file. You can find the Steve Jobs’ 2005 Standford Commencement address test file here. Then we import the text file to python.
with open('steve_jobs_speech.txt') as f: #replace the filename with your speech
speech = f.read()
print(speech)
>>'I am honored to be with you today at your commencement from one ...'
Next, we clean the speech (converting the speech to atomic elements and removing meaningless words).
from nltk.tokenize import RegexpTokenizer
from nltk.corpus import stopwords
tokenizer = RegexpTokenizer(r'[A-Za-z]+')
raw = speech.lower()
tokens = tokenizer.tokenize(raw)
stop_words = stopwords.words('english') #English stop words list
stopped_tokens = [word for word in tokens if not word in stop_words] # extract all the non-meaningless words
print(stopped_tokens)
>>['honored', 'today', 'commencement', 'one', 'finest', 'universities', ...]
We need to concatenate all words in the stopped_tokens list as a speech and create the wordcloud.
from wordcloud import WordCloud
import imageio
import matplotlib.pyplot as plt
speech_new=" ".join(stopped_tokens) #concatenate all words
wordcloud = WordCloud(
mask=imageio.imread('steve_jobs.png'),
background_color="white",)
wordcloud.generate(speech_new)
plt.figure()
plt.title('How to live before you die')
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.savefig("steve_jobs_wordcloud.png", dpi =300) # you can save it as jpeg or other formats
plt.show()
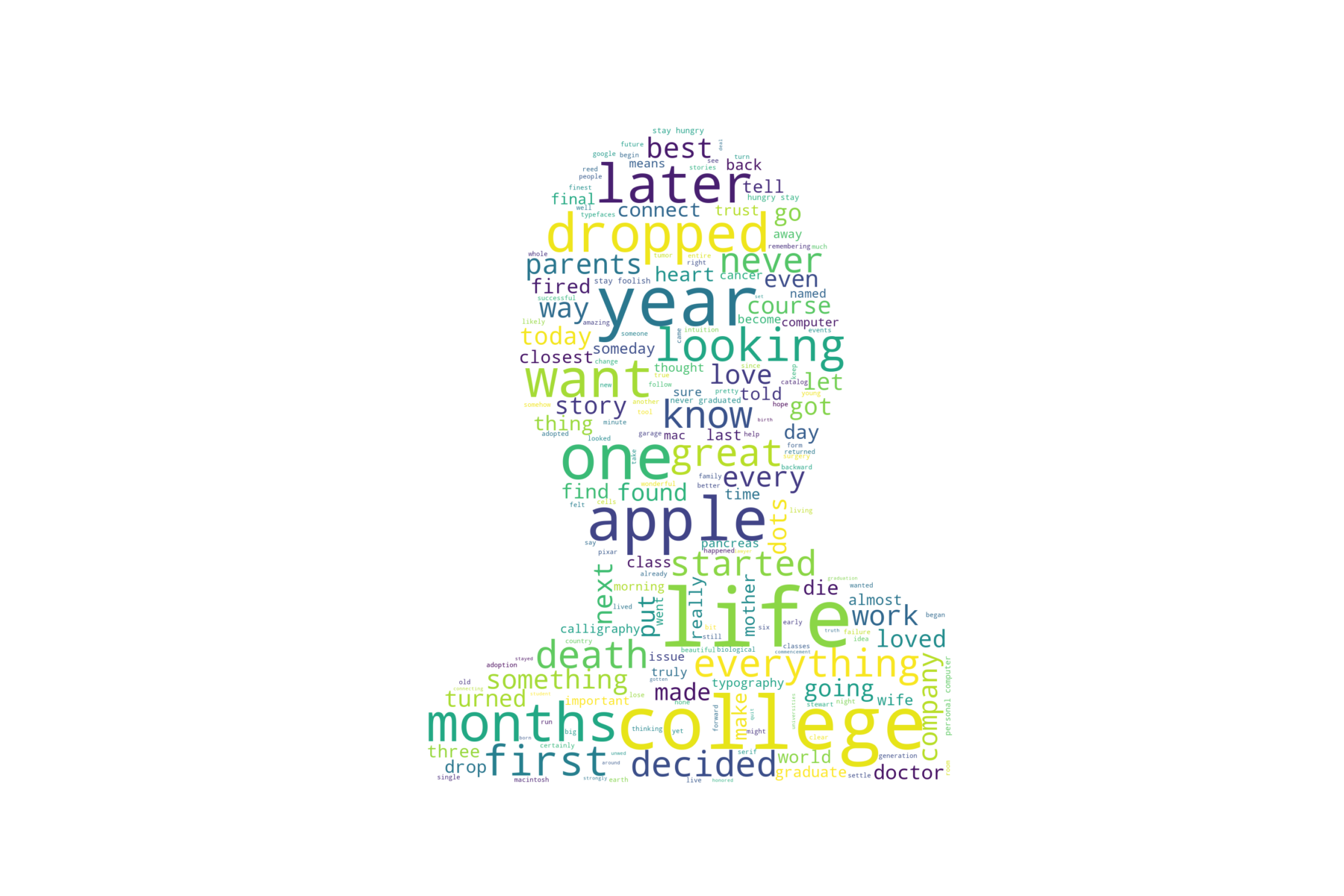
Here’s the result: